1. Цели, задачи и
компромиссы
Технология единого
источника нужна для того, чтобы выпускать качественную техническую
документацию, даже если она достаточно сложно устроена, или ее объем
достаточно велик. Теоретически любой комплект документов можно разрабатывать и
сопровождать с помощью текстового процессора, т. е.
по современным меркам вручную. Поручив это квалифицированным и добросовестным
специалистам, мы избавимся от проблем с качеством, во всяком случае, до тех
пор, пока у исполнителей будет хватать времени на самоконтроль: тщательную
проверку всех результатов, правку и повторную проверку. На практике времени
обычно не хватает. Дело не только в том, что конкуренция, бюджетные
ограничения, давление со стороны заказчика и другие внешние обстоятельства
вынуждают разработчиков выдерживать сжатые сроки, в конце концов, изыскивать
ресурсы — задача управленца. Подготовка текста требует ресурсов, которые не
раздобыть ни одному менеджеру. Ограничен ресурс человеческого внимания,
поэтому с ростом объема документов и количества взаимосвязей между ними
затраты на проверку возрастают нелинейно. Люди не телепаты[1], поэтому совместная работа
нескольких авторов приводит к разнобою в документах. Вопреки стараниями
разработчиков в техническую документацию закрадываются ошибки. Нарушаются
правила оформления, одни и те же сведения в разных документах излагаются
по-разному, документы обновляются несвоевременно, или обновленные части
перемешиваются с устаревшими. Иными словами, теряется устойчивость качества: к нему можно стремиться, но за
него невозможно ручаться. Особенно остро это проявляется при сопровождении
больших комплектов технической документации.
Первая мера, на которую
идут, чтобы все-таки удержать качество на должном уровне, — упрощение
комплекта. Если не получается эффективно исправлять ошибки, то надо сузить для
них «среду обитания». Всякое дублирование информации запрещается. Количество
перекрестных ссылок сводится к минимуму. От информационно-поискового аппарата
в линейных документах и навигации в гипертекстовых отказываются, ограничиваясь
оглавлением. Это выход из положения, но плохой, потому что расплачивается за
него пользователь. Он получает формально качественные документы, работать с
которыми ему неудобно.
Теперь необходимо сделать
две важные оговорки. Большим объемом будем называть
такой, при котором моральные и профессиональные достоинства разработчиков
перестают гарантировать качество результатов их труда. Здесь мы предполагаем,
что с ростом объема текста и его структурной сложности (которая
характеризуется количеством перекрестных ссылок, повторений, устойчивых
формулировок, терминов, упоминаемых названий), любой проект рано или поздно
перейдет эту грань. Качество будем сводить к набору
измеримых показателей, для каждого из которых можно установить минимальный
порог, и, если он не достигнут, то документ (или комплект) считается
неудовлетворительным. Например, все списки должны быть оформлены с
определенным отступом от левого поля, сведения только для службы технической
поддержки никогда не должны включаться в документацию конечного пользователя,
выводимые программой сообщения должны цитироваться в документации точно и
т. д. Измерять стилистику или логичность изложения
мы не умеем, таким образом, на самом деле речь идет в важных, но не
исчерпывающих характеристиках качества технической документации.
В
противоположность упрощению комплекта подход единого источника предполагает
автоматизацию труда разработчика, а не отказ от ручных операций заодно с их
полезными результатами. Отлаженный (!) автомат не совершает случайных ошибок,
свойственных людям, поэтому проверять, править и перепроверять сгенерированные
им документы не нужно вообще. Правда, в некоторых видах работ современные
автоматы не в состоянии превзойти даже человека средних способностей:
посредственный верстальщик верстает лучше, чем самый совершенный автомат. В
каком смысле лучше? Адекватнее нашему восприятию, естественнее. Автомат
соблюдает правила всегда, человек же нарушает их, заметив, что здесь и сейчас
они действуют против тех целей, на достижение которых изначально направлены.
Скажем, особенности конкретной полосы таковы, что бездумное применение
некоторого правила типографики делает ее менее эстетичной.
Итак,
первая цель — устойчивость качества, первый компромисс — согласие не известную
формальность результата ради устранения формальных же
ошибок.
Часто говорят, что единый источник ускоряет и
удешевляет разработку технической документации. Спорное утверждение, поскольку
за ускорение и удешевление одних операций мы расплачиваемся появлением
дополнительных. В любом случае это не самостоятельные его преимущества, а
другое выражение устойчивости качества. Неудовлетворительная документация
никому не нужна даже мгновенно и бесплатно, а комфорт исполнителя сам по себе,
как правило, не является целью проекта или организации. Ускорение и
удешевление достигаются по сравнению с непредсказуемо долгим исправлением
ошибок при ручной работе над большим комплектом. Очевидно, разработка
обозримого (не «большого» в нашем смысле) комплекта традиционными средствами
обходится дешевле, чем с использованием сложной технологии.
Отсюда второй компромисс — согласие на управляемый рост затрат
в начале проекта ради предотвращения неуправляемого в
конце.
Автоматизация разработки технической документации
вызвана к жизни борьбой с проблемами, которые поражают любой крупный проект.
Вместе с тем она открывает возможности, которые позволяют ставить новые
позитивные цели, как то:
- повышение информативности технической документации;
- сокращение сроков доставки актуальной технической документации
пользователям;
- предоставление пользователям инструмента для фиксации своего опыта или
установившейся практики работы.
Технологии единого источника позволяют решать следующие
задачи:
-
Автоматизация оформления документов по заданному макету или
стандарту.
Предполагается как публикация серии документов по одному хорошо
отлаженному макету, так и публикация одного документа по нескольким
макетам, допустим, руководство пользователя оформляется по ГОСТ 2.105-95 для поставки
государственному заказчику и в соответствии с корпоративным стандартом для
выпуска продукта в розницу. Документы как таковые и описания макетов при
этом создаются и хранятся раздельно.
-
Публикация документа в разных электронных форматах.
Описания продуктов размещаются на веб-сайте в формате HTML и
передаются типографии для тиражирования в формате PostScript.
Многоплатформенное решение может комплектоваться документацией в форматах,
специфичных для разных сред: CHM для Microsoft
Windows и man pages для Unix.
Другой типичный случай — создание руководства пользователя и хелп-файла на
основе одного и того же текста.
-
Автоматизация компоновки документов.
Устранение физического дублирования текста при сохранении его
вхождений в разные документы. Условный текст, в том числе, профилирование текста по аудитории, платформам,
операционным системам. Автоматизированное формирование структур
документов.
-
Создание функциональных электронных документов.
В основном это веб-публикации с развитыми средствами навигации и
поиска, базы знаний наподобие MSDN.
-
Формирование информационно-поискового аппарата.
К информационно-поисковому аппарату относятся оглавления,
всевозможные указатели, перекрестные ссылки и т. п.
В комплект, состоящий из нескольких документов, полезно включать
объединенное оглавление и объединенный предметный указатель. Также бывают
необходимы перекрестные ссылки между документами. Реализация этих
возможностей средствами обычных текстовых процессоров отнимала бы у
авторов слишком много времени.
-
Интеграция документирования с разработкой.
Будучи связаны административно, эти процессы нередко полностью
изолированы друг от друга технологически. Управление требованиями,
управление конфигурациями, версионный контроль, трассировка ошибок для
технической документации и документируемого решения выполняются
параллельно. Дублирование функций не экономично и неудобно. Кроме того,
документы и программы могут иметь общие компоненты, например, тексты
сообщений, которые и отображаются в интерфейсе пользователя, и упоминаются
в документации. Очевидно, разработчики могут время от времени
редактировать их, поэтому, если не сделать соответствующий ресурс общим,
то придется постоянно сверять документацию с программой.
2. Принцип единого
источника
2.1. Основные понятия и
определения
Выходным будем
называть электронный документ, который поставляется пользователю. Случай,
когда пользователь работает с твердой копией, даже если это книга,
отпечатанная в типографии, не рассматривается как отдельный, потому что
твердая копия производится на основе электронного документа. Формат файла
выходного документа называется целевым. Внешний
вид, графическое оформление выходного документа будем называть макетом [2]. Набор правил построения макета называется принципиальным макетом. Свойства принципиального макета
и технические свойства выходного документа, связанные с целевым форматом
(например, средства навигации в PDF-файле), обобщенно будем называть оформлением.
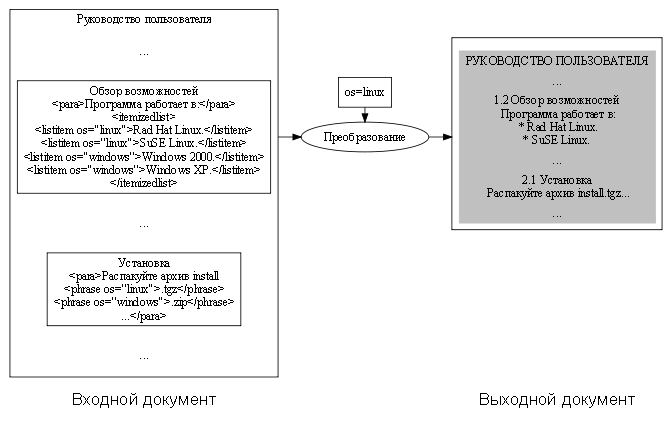
Взятую отдельно смысловую часть
документа, т. е. выходной документ за исключением
оформления, будем называть входным документом. Если
входной документ и данные об оформлении хранятся раздельно, то выходной
документ формируется в результате определенного преобразования (рис. 1).
Преобразование может представлять собой цепочку преобразований, выполняемых друг за другом.
Тогда каждое из них кроме последнего формирует промежуточный документ, который подается на вход
следующему в цепочке (рис. 2). При этом каждое
преобразование может использовать относящуюся именно к нему часть данных об
оформлении.
Большие
объемы технической документации разрабатываются не в одиночку и не сразу.
Поэтому единый источник не сводится к чистой технологии, это еще и
определенный способ организации работы специалистов, участвующих в
документировании. Всех, кто составляет текст технической документации, будем
называть авторами. При этом, говоря о тексте, будем
иметь в виду и собственно текст, и относящиеся к нему материалы, в том числе,
рисунки. Авторами могут быть не только профессиональные технические писатели,
но и специалисты, для которых документирование только одна из их функций.
Принципиальный макет либо создается дизайнером,
либо продиктован стандартом, скажем, ГОСТ 2.105-95 [1]. Технически оформление реализуется программистом. Он умеет описывать принципиальные макеты
тем способом, который «понятен» программам, выполняющим преобразования.
Автора, ответственного за успех подготовки документов, будем называть редактором (он руководит авторами, но о его функциях и
полномочиях разговор отдельный). Мы предполагаем, что документирование
проводится в рамках некоторого проекта. У проекта
обязательно есть заказчик, он может быть внутренним
или внешним по отношению ко всей организации, но по отношению к самому проекту
он в любом случае внешний. Заказчик диктует требования к технической документации, причем некоторые
из них, например, соответствие документов определенному стандарту, подлежат
безусловному выполнению. «Бесконечную» деятельность по развитию некоторого
технического решения (автоматизированной системы, программного продукта) будем
рассматривать как серию проектов.
2.2 Содержание,
структура, оформление
Единый источник вне зависимости
от его технической реализации содержит все фрагменты, которые могут быть включены в
разрабатываемые документы. Объем фрагмента определяется его предполагаемой
функцией, фрагментом может быть целая глава, а может ячейка таблицы. Обычно от
фрагментов, несущих одну функцию, требуют единообразной структуры, например,
все функции API должны быть описаны по одному плану. Для каждого фрагмента в
едином источнике должна храниться ровно одна копия. Фрагмент обязательно
снабжается уникальным идентификатором, по которому
к нему можно получить доступ. Допускается выделение внутри фрагмента других
фрагментов. Последнее не означает, что фрагмент, содержащий другие фрагменты,
целиком из них состоит, просто его частям, представляющим самостоятельный
интерес, присваиваются уникальные идентификаторы. В крупных проектах фрагменты
чаще образуют лес, а не дерево. Последовательность разработки фрагментов и их
загрузки в единый источник не имеет значения. Не существенен и способ хранения
фрагмента, такие детали, как число и взаимное расположение XML-файлов,
которыми представлен фрагмент, должны касаться только его автора.
Шаблон документа задает структуру его разделов и состав
включаемых в него фрагментов. Кроме заголовков и метаданных шаблон не содержит
собственного текста. Его место занимают включающие
ссылки на фрагменты единого источника. Включающая ссылка может явно
указывать на фрагмент с определенным значением уникального идентификатора или
содержать запрос на выборку фрагментов, удовлетворяющих определенным условиям.
Во избежание терминологической путаницы напомним, что применительно к
текстовым процессорам шаблоном обычно называют образец оформления любых
документов некоторого типа, например, в поставку текстового процессора Microsoft Word входят шаблоны
писем, резюме, служебных записок и даже технической документации. В нашем
случае у каждого конкретного документа должен быть свой шаблон, причем к
оформлению он как раз не имеет отношения.
Шаблон и все фрагменты, на
которые он прямо или косвенно ссылается, в совокупности составляют входной
документ.
В общем случае структура входного документа
«глубже» структуры шаблона, потому что любой фрагмент может иметь собственную
структуру.
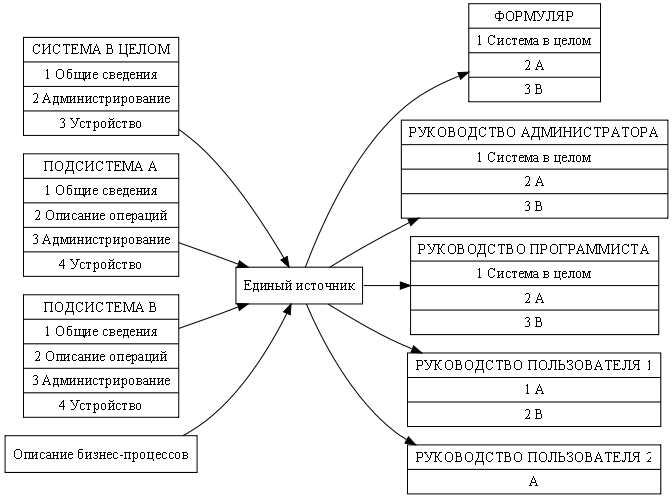
Таким образом, каждый документ можно разложить на три
обязательных составляющих: содержание, структуру и оформление (рис. 3).
Назвать
эти составляющие абсолютно независимыми друг от друга было бы преувеличением,
но выделить разработку каждой из них в самостоятельную задачу внутри проекта,
как правило, возможно. Что это дает?
- Содержание и структура изолированы от оформления. Их можно
разрабатывать параллельно, сокращая критический путь проекта. Вдобавок
модификация одной из этих составляющих никогда не приводят к сбоям в
другой: авторы заведомо не испортят оформление, а «оформитель» текст.
- Разработка содержания легко распределяется между несколькими авторами.
При обновлении фрагментов не требуется повторно вставлять их во входной
документ. Если фрагмент входит в несколько входных документов, то
расхождения между последними по этому фрагменту заведомо исключены.
- Полученные результаты можно использовать многократно. Из одних и тех
же выверенных фрагментов можно формировать документы, предусмотренные
ГОСТ, RUP или MSF. Одни и те же документы можно оформлять по-разному и
распространять в разных форматах. Одни и те же отлаженные правила
оформления можно использовать для разных документов и даже в разных
проектах и т. д.
В документировании, как и в программировании, изоляция
участков работы и повторное использование отлаженных результатов обеспечивают
устойчивость качества.
2.3. Единый источник как база
знаний
Атрибутизация фрагментов и создание механизмов
их поиска по значениям полей позволяет
рассматривать единый источник как базу данных. Тогда выходной документ можно
сравнить с отчетом, а шаблон документа — с формой отчета. Поля могут содержать
данные об аудитории, теме или состоянии фрагмента. Например, фрагмент помечают
как адресованный только квалифицированным или только начинающим пользователям,
как относящийся только к определенной версии продукта, как завершенный или
незавершенный. Также в поля можно выносить важные сведения о предмете
описания, разумеется, когда их удается формализовать. Допустим, если фрагмент
говорит о некоторой функции автоматизированной системы, то в специальное поле
можно поместить список пользовательских ролей, которые к этой функции
обращаются.
Атрибутизация фрагментов позволяет:
- профилировать документы по разным признакам;
- организовать проблемно-ориентированный поиск;
- организовать проблемно-ориентированную навигацию.
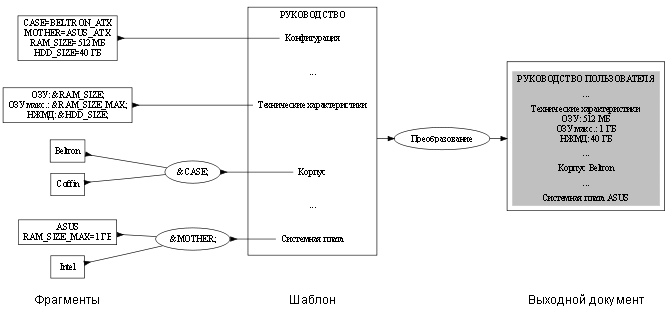
Профилированием называется
автоматический отсев фрагментов по заданным признакам при формировании
выходного документа (рис. 4). Обычно профилирование применяется,
когда необходимо подготовить несколько редакций одного и того же документа для
разных аудиторий, причем различия между редакциями заключаются во множестве
небольших по объему фрагментов, касающихся важных деталей. Например,
руководство пользователя адресовано и службе технической поддержки, и конечным
пользователям, но последних лучше не знакомить с особенностями защиты от
копирования или редко возникающими проблемами. Другой типичный случай
профилирования — руководства по приложениям, имеющим параллельные версии для
разных аппаратных платформ и операционных систем. Встречается профилирование
по последовательным версиям самого документируемого решения, если эти версии
выпускаются часто и отличаются друг от друга незначительно.
Проблемно-ориентированный поиск обеспечивает
пользователю возможность быстро ориентироваться во взаимосвязях между частями
или свойствами технического решения. Распространенный пример
проблемно-ориентированного поиска — размещаемый в конце каждого раздела список
перекрестных ссылок на ассоциативно связанные разделы, обычно он имеет
подзаголовок «См. также». Такие списки могут формироваться авторами вручную, а
могут автоматически по общим для связываемых разделов ключевым словам. К
средствам проблемно-ориентированного поиска мы относим указатели специального
вида, предположим, указатель функций API в руководстве
программиста или указатель первичных документов в руководстве по
ERP-системе.
Проблемно-ориентированная
навигация не только позволяет быстро найти нужные сведения, но и сама по
себе информативна. Если техническое решение состоит из большого количества
компонент, то можно построить схему, иллюстрирующую характер взаимосвязей
между ними, допустим, дерево зависимостей или диаграмму потоков данных,
снабдив каждый элемент этой схемы гипертекстовой ссылкой на соответствующий
раздел. Если система автоматизирует какой-нибудь бизнес-процесс, то можно
построить диаграмму бизнес-процесса, разметив ее гипертекстовыми ссылками на
технологические
инструкции по выполнению отдельных операций.
Перечисленные
возможности в совокупности позволяют обращаться с единым источником как с
базой знаний о техническом решении. Поддержание полноты и актуальности базы
знаний выходит на первый план, а формирование выходных документов становится
вспомогательной задачей, быстро решаемой в случае необходимости.
4.1. Документирование
корпоративной информационной системы
Под корпоративной информационной системой (КИС) или автоматизированной системой (АС) [7] здесь понимается решение,
полностью или частично автоматизирующее деятельность некоторой организации.
Подчеркнем, что АС включает в себя и программы, и данные, и аппаратные
средства, и участвующий в автоматизированных бизнес-процессах персонал [3, 7]. Иными словами,
завершенная АС обязательно внедрена, она не продается «в коробке», хотя может
создаваться на основе тиражируемого программного
продукта.
Документирование АС обычно обусловлено следующими
обстоятельствами:
- Разные компоненты АС (модули, функциональные подсистемы) могут
создаваться в разное время разными командами, что объясняется постепенным
изменением потребностей бизнеса, необходимостью планирования бюджета и
загруженностью разработчиков.
- Документация на АС не сводится к технической документации на входящие
в ее состав программы, обязательно должна быть описана технология
выполнения бизнес-процессов с помощью системы.
- Постоянное изменение обстановки, в которой действует организация,
вынуждает модифицировать АС и автоматизированные бизнес-процессы, при этом
необходимо поддерживать актуальность документации.
- Аудитория документации на АС, т.е. сотрудники, которые непосредственно
работают с ней, а также обеспечивают ее эксплуатацию и сопровождение,
могут быть распределены по территориально удаленным друг от друга офисам
организации.
- Документация на АС включена в документооборот организации, она может
проходить согласование и утверждение, отдельные документы могут
приобретать нормативное значение, выдаваться сотрудникам для ознакомления
под роспись, предоставляться внешним и корпоративным аудиторам и т.
п.
Это заставляет предъявлять к документации и процессу
документирования противоречивые требования:
- Такие документы, как формуляр, руководство администратора или руководство программиста, должны содержать
необходимые сведения обо всех компонентах АС и взаимосвязях между ними.
Если АС достаточно сложна, для каждой пользовательской роли разрабатывают
отдельное руководство, причем одна и та же пользовательская роль может
требовать обращения к разным компонентам. Вместе с тем, документирование
компонентов АС — часть их разработки, а разрабатываются они по
отдельности.
- Пользователям должно быть удобно работать с документацией, а
разработчикам сопровождать ее. В интересах
первых руководства пользователя следовало бы объединить с описаниями
бизнес-процессов, а в интересах вторых — вынести описания бизнес-процессов
в отдельный документ.
- Чтобы сотрудники всегда имели доступ к самой последней версии
документации, ее нужно публиковать на интранет-сайте, однако, нормативные
и отчетные документы должны быть представлены твердыми копиями,
оформленными согласно традиции или определенному стандарту.
Информация возникает и фиксируется в одном порядке, а
потребляется в другом, причем разные аудитории нуждаются в разных форматах ее
представления. Необходим механизм перегруппировки и дублирования информации.
Реализовать его можно, в частности, с помощью технологии единого источника:
Схематически предложенное решение показано на рис. 8.
4.2. Документирование комплектуемого
решения
Комплектуемое
решение поставляется потребителю в одном из возможных вариантов,
количество которых комбинаторно. Типичный пример комплектуемого решения —
PC-совместимый компьютер. Он состоит из определенных функциональных блоков
(корпуса, системной платы, процессора, модулей оперативной памяти, жесткого
диска и др.), причем их модели и технические характеристики варьируются от
поставки к поставке. В действительности сочетаемость
блоков ограничена: одни должны присутствовать обязательно, другие могут быть
взаимоисключающими или, наоборот, устанавливаться только совместно, но для нас
это сейчас не существенно. Важно, что эксплуатационная документация на такое
решение тоже должна комплектоваться, поставлять ее в избытке практически
невозможно, потому что избыточность получится огромной.
Далее для
простоты изложения будем предполагать, что комплект эксплуатационной
документации состоит из единственного документа, руководства по
эксплуатации. Другие
документы, например, паспорт или спецификация [2], формируются аналогично.
Простейший способ
комплектовать руководство по эксплуатации — создать шаблон с унифицированной
структурой разделов и вручную заполнять его включающими ссылками на фрагменты
единого источника, содержащие описания моделей блоков, поставляемых в составе
конкретной конфигурации. У этого способа есть два весомых недостатка.
Во-первых, для каждой конфигурации фактически придется разрабатывать отдельный
шаблон. Во-вторых, технические характеристики конфигурации тоже придется
указывать вручную, что ведет к тиражированию разделов, в которых они
приводятся. Очевидно, этот способ трудоемок и чреват многочисленными ошибками,
особенно учитывая, что некоторые технические характеристики конфигурации
зависят от моделей блоков, например, максимальный объем оперативной памяти —
свойство системной платы.
Технически сложнее, но намного эффективнее
сделать руководство пользователя параметрическим. Автор, публикующий
руководство на очередную конфигурацию, не будет редактировать ни шаблон, ни
фрагменты единого источника, вместо этого он укажет значения параметров конфигурации. При формировании выходного
документа они автоматически подставятся в него.
Предусмотрены три
категории параметров конфигурации:
-
структурные;
-
свободные;
-
связанные.
Структурный параметр содержит
идентификатор (условное обозначение, принятое в рамках проекта) модели
включаемого в конфигурацию блока определенного типа, допустим, корпуса или
системной платы. По идентификатору фрагмент с описанием блока извлекается из
единого источника при обработке входного документа. Если блок некоторого типа
отсутствует в конфигурации, то соответствующему структурному параметру следует
присвоить пустое значение.
Свободный параметр
содержит значение, которое варьируется от конфигурации к конфигурации.
Свободными параметрами могут быть, например, объем установленной оперативной
памяти, емкость жесткого диска, тактовая частота процессора, гарантийный
срок.
Связанный параметр содержит значение,
определяемое моделью какого-нибудь блока. Так, максимальный объем оперативной
памяти, максимальное количество процессоров, габариты корпуса — связанные
параметры.
Все значения структурных и свободных параметров указываются в
едином файле конфигурации. Значения связанных
параметров указываются непосредственно во фрагментах с описаниями блоков.
Шаблон руководства, как обычно, содержит включающие ссылки на фрагменты
единого источника, однако, они выражены через значения структурных параметров.
Фрагменты единого источника могут содержать ссылки на параметры, иными
словами, они «экспортируют» значения связанных параметров и «импортируют»
значения свободных и связанных параметров.
Схема формирования
параметрического руководства пользователя приведена на рис. 9.